 In the ISO research project for my MSc in Machine Learning at Imperial College London, I focused on the problem of Cluster Analysis by using Dirichlet Process Mixture Models. The DPMMs is a “fully-Bayesian” unsupervised learning technique which unlike other Cluster Analysis methods does not require us to predefine the total number of clusters within our data. Large companies, such as Google, use these infinite Dirichlet mixture models in a variety of applications including Document Classification, Natural Language Processing, Computer Vision and more.
In the ISO research project for my MSc in Machine Learning at Imperial College London, I focused on the problem of Cluster Analysis by using Dirichlet Process Mixture Models. The DPMMs is a “fully-Bayesian” unsupervised learning technique which unlike other Cluster Analysis methods does not require us to predefine the total number of clusters within our data. Large companies, such as Google, use these infinite Dirichlet mixture models in a variety of applications including Document Classification, Natural Language Processing, Computer Vision and more.
Update: The Datumbox Machine Learning Framework is now open-source and free to download. Check out the package com.datumbox.framework.machinelearning.clustering to see the implementation of Dirichlet Process Mixture Models in Java.
During my research I had the opportunity to work with two different mixture models: the Multivariate Normal Mixture Model which is used for clustering continuous Gaussian datasets and the Dirichlet-Multinomial Mixture Model which is used for clustering Documents. The original research lasted for 3 months and was performed under the supervision of Professor Aldo Faisal from Imperial College London. My plan is within the next weeks to post an adapted version of my research in this blog, discuss the theory and applications of Dirichlet Process Mixture Models and publish a Java implementation which can be used to perform clustering with DPMMs.
This article is the introduction/overview of the research, describes the problems, discusses briefly the Dirichlet Process Mixture Models and finally presents the structure of the upcoming articles.
Cluster Analysis is an unsupervised learning technique which targets in identifying the groups within a dataset. The groups are selected in such a way so that the observations assigned to them are more similar to each other than to the observations which belong to different groups. Clustering is an unsupervised technique because it does not make use of annotated datasets in order to estimate the aforementioned clusters. Instead the clusters are identified only by using the characteristics/features of the data.
The task of cluster analysis is not linked directly to a particular algorithm but rather there are several different approaches to model the data. In the literature we can find centroid models (such as the K-means and the K-representative) which represent the groups as mean vectors, distribution models (such as the Mixture of Gaussians) which model the generative distributions of the data by using statistics and probabilities, Graph Clustering models (such as the MCL) which organize datasets on the basis of the edge structure of the observations, Connectivity models (such as the Agglomerative and Divisive algorithms) which focus on the distance connectivity and more.
Cluster Analysis algorithms can be further separated in different categories depending on the way that they organize the clusters. For example algorithms can divided based on whether they perform hard or soft clustering (assigning the data points to a single cluster or to many clusters with a certain probability/weight) and on whether they perform flat, hierarchical or overlapping clustering (whether preserve a hierarchy in the identified clusters).
Finally given the fact that Cluster Analysis is one of the most popular and regularly used Machine Learning techniques, several different algorithms and models have been proposed in the literature. In general the technique that is used in each case heavily depends on the problem and the type of data that we have.
Due to the fact that Cluster Analysis does not require having annotated datasets which are usually expensive and difficult to find, it has become a powerful tool in many different areas of science and business. As a result Clustering has numerous applications in a large number of different fields.
In computer vision clustering is frequently used in image segmentation and in grouping together different objects within a scene. In bioinformatics and neuroscience it can be used to group together genes or neurons that are associated to particular tasks/behaviors. In marketing and business clustering it is regularly used to identify groups within customer databases and enable companies to offer more targeted services. Search engines use clustering in order to identify similar documents within their indexes and organize webpages in categories. Social Networks use clustering to identify communities and cliques within large groups of users. Finally we should note that Cluster Analysis has been successfully applied in several other areas such Medicine, Computer science, Finance, Social Sciences, Robotics, Physics and more.
One of the most difficult problems in clustering is determining the total number of clusters that exist within the data. In general many of the existing algorithms require the total number of clusters k as a parameter before performing the analysis and their results heavily depend on this parameter. When the number of clusters k is known before hand, then the aforementioned algorithms are able to provide us with the required cluster assignments. Nevertheless this number is rarely known in real-world applications. Additionally in many applications the number of clusters is expected to change as we add more observations over time.
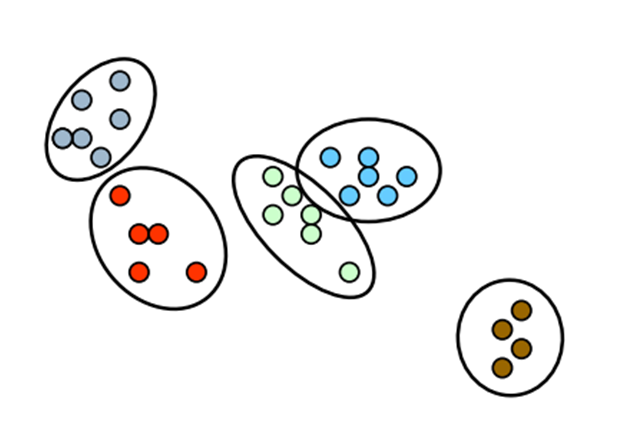
Even though several techniques have been proposed to avoid specifying directly the number of clusters (Agglomerative Hierarchical Clustering) or to estimate the optimal number of clusters from data (such as X-means), most of the techniques relay heuristics and they don’t use the probabilistic framework. One alternative approach which allows us to estimate dynamically the number of clusters and adapt it as more data are observed is to use Dirichlet Processes Mixture Models.
The Dirichlet process is a family of non-parametric Bayesian models which are commonly used for density estimation, semi-parametric modelling and model selection/averaging. The Dirichlet processes are non-parametric in a sense that they have infinite number of parameters. Since they are treated in a Bayesian approach we are able to construct large models with infinite parameters which we integrate out to avoid overfitting. It can be shown that DPs can be represented in different ways all of which are mathematically equivalent. Few common ways to represent a Dirichlet process is with the Blackwell-MacQueen urn scheme, the Stick-breaking construction and the Chinese Restaurant Process.
Dirichlet Process Mixture Models can be constructed in order to perform clustering in sets of data. With DPMMs we construct a single mixture model in which the number of mixture components is infinite. This means that DPMM does not require us to define from the beginning the number of clusters (which in this case it is infinite) and it allows us to adapt the number of active clusters as we feed more data to our model over time.
As we will see in an upcoming article, representing DPMM as a Chinese Restaurant Process creates a clustering effect which we use to perform Cluster Analysis on the data. In order to estimate the cluster assignments of our model we can use Gibbs sampling and consequently we must select the appropriate conjugate priors to make the sampling possible.
The Dirichlet Process Mixture Models have become popular both in Machine Learning and in Statistics. Consequently they have been used in a large number or applications. Wood et al. have used DPMMs to perform spike sorting and identify the number of different neurons that were monitored by a single electrode. Sudderth et al. have used this model to perform Visual Scene Analysis and identify the number of objects, parts and features that a particular image contains. Liang et al. and Finkel et al. used Hierarchical Dirichlet processes in the field of Natural Language Processing in order to detect how many grammar symbols exist in a particular set of sentenses. Finally Blei et al. and Teh et al. have used similar hierarchical models in order to cluster documents based on their semantic categories.
The DPMMs become increasigly popular and an active area of research. They have been applied to a large number of different problems and solve many of the aformentioned limitations of Cluster Analysis within the probabilistic framework. DPMMs allow us to perform unsupervised learning by using non-parametric and fully-bayesian approach and build complicated models with Hierarchical structure.
Therefore in this series of articles I will focus on presenting the mathematical foundations of the model, discuss the various representations of Direclet Processes, introduce 2 different models the Multivariate Normal Mixture Model and the Dirichlet-Multinomial Mixture Model that can be used for clustering continuous data and documents and finally I will present my Java implementation and the results of demos.
This series of articles will follow the same structure as my research report and it will be organized in the following segments:
Stay tuned for the upcoming articles! I hope you enjoyed this post; if you did please take a moment to share the article on Facebook and Twitter. 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more








Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


Hi Hu,
Rest assured the next posts will be more technical meaning, they will describe in detail the mathematical model, the representation of the DP and at the end there will be a Java implementation both for continuous data and for text processing. 🙂 This was just a non-technical introduction to put things into perspective.
Stay tuned.
Vasilis
Thanks Rod, I will look into it. 🙂
Hi Vasilis,
This is a great resource for anyone starting to learn about these models. I have two questions:
1.) It is slightly unclear how the cluster parameters are sampled in the method you describe. Are random cluster parameters and cluster assignments simultaneously generated?
2.) How well does this method scale to very large datasets and more dimensions, and can it handle uncertainties on the data values x_i with some modification?
Many Thanks,
Aaron