 By now most of you have heard/played the 2048 game by Gabriele Cirulli. It’s a simple but highly addictive board game which requires you to combine the numbers of the cells in order to reach the number 2048. As expected the difficulty of the game increases as more cells are filled with high values. Personally even though I spent a fair amount of time playing the game, I was never able to reach 2048. So the natural thing to do is to try to develop an AI solver in JAVA to beat the 2048 game. 🙂
By now most of you have heard/played the 2048 game by Gabriele Cirulli. It’s a simple but highly addictive board game which requires you to combine the numbers of the cells in order to reach the number 2048. As expected the difficulty of the game increases as more cells are filled with high values. Personally even though I spent a fair amount of time playing the game, I was never able to reach 2048. So the natural thing to do is to try to develop an AI solver in JAVA to beat the 2048 game. 🙂
In this article I will briefly discuss my approach for building the Artificial Intelligence Solver of Game 2048, I will describe the heuristics that I used and I will provide the complete code which is written in JAVA. The code is open-sourced under GPL v3 license and you can download it from Github.
The original game is written in JavaScript, so I had to rewrite it in JAVA from scratch. The main idea of the game is that you have a 4×4 grid with Integer values, all of which are powers of 2. Zero valued cells are considered empty. At every point during the game you are able to move the values towards 4 directions Up, Down, Right or Left. When you perform a move all the values of the grid move towards that direction and they stop either when they reach the borders of the grid or when they reach another cell with non-zero value. If that previous cell has the same value, the two cells are merged into one cell with double value. At the end of every move a random value is added in the board in one of the empty cells and its value is either 2 with 0.9 probability or 4 with 0.1 probability. The game ends when the player manages to create a cell with value 2048 (win) or when there are no other moves to make (lose).
In the original implementation of the game, the move-merge algorithm is a bit complicated because it takes into account all the directions. A nice simplification of the algorithm can be performed if we fix the direction towards which we can combine the pieces and rotate the board accordingly to perform the move. Maurits van der Schee has recently written an article about it which I believe is worth checking out.
All the classes are documented with Javadoc comments. Below we provide a high level description of the architecture of the implementation:
The board class contains the main code of the game, which is responsible for moving the pieces, calculating the score, validating if the game is terminated etc.
The ActionStatus and the Direction are 2 essential enums which store the outcome of a move and its direction accordingly.
The ConsoleGame is the main class which allows us to play the game and test the accuracy of the AI Solver.
The AIsolver is the primary class of the Artificial Intelligence module which is responsible for evaluating the next best move given a particular Board.
Several approaches have been published to solve automatically this game. The most notable is the one developed by Matt Overlan. To solve the problem I tried two different approaches, using Minimax algorithm and using Alpha-beta pruning.
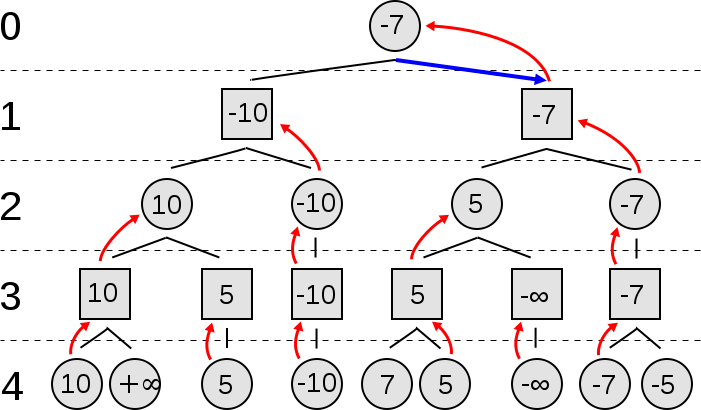
The Minimax is a recursive algorithm which can be used for solving two-player zero-sum games. In each state of the game we associate a value. The Minimax algorithm searches through the space of possible game states creating a tree which is expanded until it reaches a particular predefined depth. Once those leaf states are reached, their values are used to estimate the ones of the intermediate nodes.
The interesting idea of this algorithm is that each level represents the turn of one of the two players. In order to win each player must select the move that minimizes the opponent’s maximum payoff. Here is a nice video presentation of the minimax algorithm:
Below you can see pseudocode of the Minimax Algorithm:
function minimax(node, depth, maximizingPlayer) if depth = 0 or node is a terminal node return the heuristic value of node if maximizingPlayer bestValue := -∞ for each child of node val := minimax(child, depth - 1, FALSE)) bestValue := max(bestValue, val); return bestValue else bestValue := +∞ for each child of node val := minimax(child, depth - 1, TRUE)) bestValue := min(bestValue, val); return bestValue (* Initial call for maximizing player *) minimax(origin, depth, TRUE)
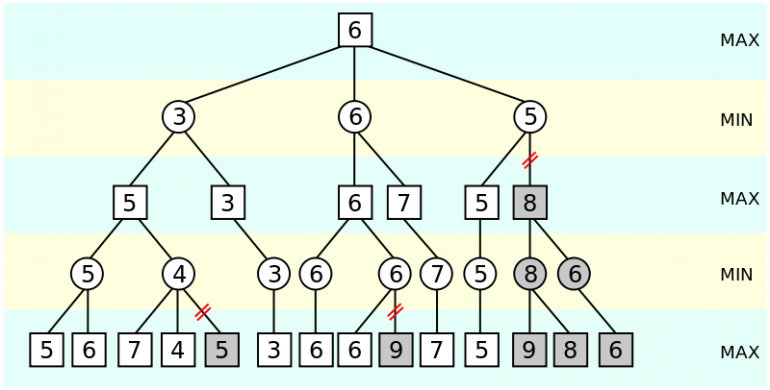
The Alpha-beta pruning algorithm is an expansion of minimax, which heavily decreases (prunes) the number of nodes that we must evaluate/expand. To achieve this, the algorithm estimates two values the alpha and the beta. If in a given node the beta is less than alpha then the rest of the subtrees can be pruned. Here is a nice video presentation of the alphabeta algorithm:
Below you can see the pseudocode of the Alpha-beta pruning Algorithm:
function alphabeta(node, depth, α, β, maximizingPlayer) if depth = 0 or node is a terminal node return the heuristic value of node if maximizingPlayer for each child of node α := max(α, alphabeta(child, depth - 1, α, β, FALSE)) if β ≤ α break (* β cut-off *) return α else for each child of node β := min(β, alphabeta(child, depth - 1, α, β, TRUE)) if β ≤ α break (* α cut-off *) return β (* Initial call *) alphabeta(origin, depth, -∞, +∞, TRUE)
In order to use the above algorithms we must first identify the two players. The first player is the person who plays the game. The second player is the computer which randomly inserts values in the cells of the board. Obviously the first player tries to maximize his/her score and achieve the 2048 merge. On the other hand the computer in the original game is not specifically programmed to block the user by selecting the worst possible move for him but rather randomly inserts values on the empty cells.
So why we use AI techniques which solve zero-sum games and which specifically assume that both players select the best possible move for them? The answer is simple; despite the fact that it is only the first player who tries to maximize his/her score, the choices of the computer can block the progress and stop the user from completing the game. By modeling the behavior of the computer as an orthological non-random player we ensure that our choice will be a solid one independently from what the computer plays.
The second important part is to assign values to the states of the game. This problem is relatively simple because the game itself gives us a score. Unfortunately trying to maximize the score on its own is not a good approach. One reason for this is that the position of the values and the number of empty valued cells are very important to win the game. For example if we scatter the large values in remote cells, it would be really difficult for us to combine them. Additionally if we have no empty cells available, we risk losing the game at any minute.
For all the above reasons, several heuristics have been suggested such as the Monoticity, the smoothness and the Free Tiles of the board. The main idea is not to use the score alone to evaluate each game-state but instead construct a heuristic composite score that includes the aforementioned scores.
Finally we should note that even though I have developed an implementation of Minimax algorithm, the large number of possible states makes the algorithm very slow and thus pruning is necessary. As a result in the JAVA implementation I use the expansion of Alpha-beta pruning algorithm. Additionally unlike other implementations, I don’t prune aggressively the choices of the computer using arbitrary rules but instead I take all of them into account in order to find the best possible move of the player.
In order to beat the game, I tried several different heuristic functions. The one that I found most useful is the following:
private static int heuristicScore(int actualScore, int numberOfEmptyCells, int clusteringScore) {
int score = (int) (actualScore+Math.log(actualScore)*numberOfEmptyCells -clusteringScore);
return Math.max(score, Math.min(actualScore, 1));
}
The above function combines the actual score of the board, the number of empty cells/tiles and a metric called clustering score which we will discuss later. Let’s see each component in more detail:
In the last line of the function we ensure that the score is non-negative. The score should be strictly positive if the score of the board is positive and zero only when the board of the score is zero. The max and min functions are constructed so that we get this effect.
Finally we should note that when the player reaches a terminal game state and no more moves are allowed, we don’t use the above score to estimate the value of the state. If the game is won we assign the highest possible integer value, while if the game is lost we assign the lowest non negative value (0 or 1 with similar logic as in the previous paragraph).
As we said earlier the clustering score measures how much scattered are the values of the board and acts like a penalty. I constructed this score in such a way so that it incorporates tips/rules from users who “mastered” the game. The first suggested rule is that you try to keep the cells with similar values close in order to combine them easier. The second rule is that high valued cells should be close to each other and not appear in the middle of the board but rather on the sides or corners.
Let’s see how the clustering score is estimated. For every cell of the board we estimate the sum of absolute differences from its neighbors (excluding the empty cells) and we take the average difference. The reason why we take the averages is to avoid counting more than once the effect of two neighbor cells. The total clustering score is the sum of all those averages.
The Clustering Score has the following attributes:
As expected the accuracy (aka the percentage of games that are won) of the algorithm heavily depends on the search depth that we use. The higher the depth of the search, the higher the accuracy and the more time it requires to run. In my tests, a search with depth 3 lasts less than 0.05 seconds but gives 20% chance of winning, a depth of 5 lasts about a 1 second but gives 40% chance of winning and finally a depth of 7 lasts 27-28 seconds and gives about 70-80% chance of winning.
For those of you who are interested in improving the code here are few things that you can look into:
Don’t forget to download the JAVA code from Github and experiment. I hope you enjoyed this post! If you did please take a moment to share the article on Facebook and Twitter. 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more








Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


Hi Athi,
Thanks for the comment. You are correct, this is indeed a bug.
What needs to be done is avoid passing a score from move, but actually return an object that gives more details on what happened inside. I will put it in my todo list. Else feel free to send me a pull request.
Regards
Vasilis
Thanks Athi,
I made few really minor modifications of your fix and I posted it online. Thank you very much for spotting the issue and for contributing the solution.
Vasilis
Hi Syed,
Yes that is correct the results of AI heavily depends on the depth that you explore. The search space is too large and thus we are forced to limit the depth of the search. This is configured by the depth parameter on the source.
Hi Si,
I have not worked much again on this project. It meant not to take more than a weekend. There are various heuristics suggested (I have a link on the post to most of them). I proposed using a variance-clustering approach which seemed to work well. I’m sure that if you are interested in solving the problem faster, there are too many other things that you can try.
Best,
Vasilis
Thanks for publishing this website – your development of software and sharing of knowledge is priceless for those of us still learning.
With that said, the algorithms used to solve 2048 are not really AI are they? These seem more like brute force algos that have been shortened because the problem space is too big (I believe minimax has been used in game theory for years – great for solving reasonable sized problems, but not AI.) I recognize there are many definitions of AI, but in this instance the algorithms are not learning from and/or tuning themselves by playing the game. My goal is to create a parameter space and have the machine tune the parameters by playing the game and learning its mistakes.
Thanks again for your website.
Here is your AI implemented on an EV3 (running leJOS) to win the game.
https://www.youtube.com/watch?v=NNmHRbG5uIw
(Depth is 5 for the first 200 moves, then 6 after that. It didn’t win the first time but it was successful on the 2nd attempt.)