 Deep Learning (the favourite buzzword of late 2010s along with blockchain/bitcoin and Data Science/Machine Learning) has enabled us to do some really cool stuff the last few years. Other than the advances in algorithms (which admittedly are based on ideas already known since 1990s aka “Data Mining era”), the main reasons of its success can be attributed to the availability of large free datasets, the introduction of open-source libraries and the use of GPUs. In this blog post I will focus on the last two and I’ll share with you some tips that I learned the hard way.
Deep Learning (the favourite buzzword of late 2010s along with blockchain/bitcoin and Data Science/Machine Learning) has enabled us to do some really cool stuff the last few years. Other than the advances in algorithms (which admittedly are based on ideas already known since 1990s aka “Data Mining era”), the main reasons of its success can be attributed to the availability of large free datasets, the introduction of open-source libraries and the use of GPUs. In this blog post I will focus on the last two and I’ll share with you some tips that I learned the hard way.
TensorFlow is a very popular Deep Learning library developed by Google which allows you to prototype quickly complex networks. It comes with lots of interesting features such as auto-differentiation (which saves you from estimating/coding the gradients of the cost functions) and GPU support (which allows you to get easily a 200x speed improvement using decent hardware). Moreover it offers a Python interface which means that you can prototype quickly without requiring to write C or CUDA code. Admittedly there are lots of other frameworks one can use instead of TensorFlow, such as Torch, MXNet, Theano, Caffe, Deeplearning4j, CNTK, etc but it all boils down to your use-case and your personal preference.
But why Keras? For me using directly TF is like doing Machine Learning with Numpy. Yes it is feasible and from time to time you have to do it (especially if you write custom layers/loss-functions) but do you really want to write code that describes the complex networks as a series of vector operations (yes, I know there are higher-level methods in TF but they are not as cool as Keras)? Also what if you want to move to a different library? Well then you would probably need to rewrite the code, which sucks. Ta ta taaa, Keras to the rescue! Keras allows you to describe your networks using high level concepts and write code that is backend agnostic, meaning that you can run the networks across different deep learning libraries. Few things I love about Keras is that it is well-written, it has an object oriented architecture, it is easy to contribute and it has a friendly community. If you like it, say thank you to François Chollet for developing it and open-sourcing it.
Without further ado, let’s jump to a few tips on how to make the most of GPU training on Keras and a couple of gotchas that you should have in mind:
Training models on GPU using Keras & Tensorflow is seamless. If you have an NVIDIA card and you have installed CUDA, the libraries will automatically detect it and use it for training. So cool! But what if you are a spoilt brat and you have multiple GPUs? Well unfortunately you will have to work a bit to achieve multi-GPU training.
![]()
There are multiple ways to parallelise a network depending on what you want to achieve but the main two approaches is model and data parallelization. The first can help you if your model is too complex to fit in a single GPU while the latter helps when you want to speed up the execution. Typically when people talk about multi-GPU training they mean the latter. It used to be harder to achieve but thankfully Keras has recently included a utility method called mutli_gpu_model which makes the parallel training/predictions easier (currently only available with TF backend). The main idea is that you pass your model through the method and it is copied across different GPUs. The original input is split into chunks which are fed to the various GPUs and then they are aggregated as a single output. This method can be used for achieving parallel training and predictions, nevertheless keep in mind that for training it does not scale linearly with the amount of GPUs due to the required synchronization.
When you do multi-GPU training pay attention to the batch size as it has multiple effects on speed/memory, convergence of your model and if you are not careful you might corrupt your model weights!
Speed/memory: Obviously the larger the batch the faster the training/prediction. This is because there is an overhead on putting in and taking out data from the GPUs, so small batches have more overhead. On the flip-side, the larger the batch the more memory you need in the GPU. Especially during training, the inputs of each layer are kept in memory as they are required on the back-propagation step, so increasing your batch size too much can lead to out-of-memory errors.
Convergence: If you use Stochastic Gradient Decent (SGD) or some of its variants to train your model, you should have in mind that the batch size can affect the ability of your network to converge and generalize. Typical batch sizes in many computer vision problems are between 32-512 examples. As Keskar et al put it, “It has been observed in practice that when using a larger batch (than 512) there is a degradation in the quality of the model, as measured by its ability to generalize.”. Note that other different optimizers have different properties and specialized distributed optimization techniques can help with the problem. If you are interested in the mathematical details, I recommend reading Joeri Hermans’ Thesis “On Scalable Deep Learning and Parallelizing Gradient Descent”.
Corrupting the weights: This is a nasty technical detail which can have devastating results. When you do multi-GPU training, it is important to feed all the GPUs with data. It can happen that the very last batch of your epoch has less data than defined (because the size of your dataset can not be divided exactly by the size of your batch). This might cause some GPUs not to receive any data during the last step. Unfortunately some Keras Layers, most notably the Batch Normalization Layer, can’t cope with that leading to nan values appearing in the weights (the running mean and variance in the BN layer). To make the things even nastier, one will not observe the problem during training (while learning phase is 1) because the specific layer uses the batch’s mean/variance in the estimations. Nevertheless during predictions (learning phase set to 0), the running mean/variance is used which in our case can become nan leading to poor results. So do yourself a favour and always make sure that your batch size is fixed when you do multi-GPU training. Two simple ways to achieve this is either by rejecting batches that don’t match the predefined size or repeat the records within the batch until you reach the predefined size. Last but not least keep in mind that in a multi-GPU setup, the batch size should be a multiple of the number of available GPUs on your system.
Typically the most expensive part while training/predicting Deep networks is the estimation that happens on the GPUs. The data are preprocessed in the CPUs on the background and they are fed to the GPUs periodically. Nevertheless one should not underestimate how fast the GPUs are; it can happen that if your network is too shallow or the preprocessing step is too complex that your CPUs can’t keep up with your GPUs or in other words they don’t feed them with data quickly enough. This can lead to low GPU utilization which translates to wasted money/resources.
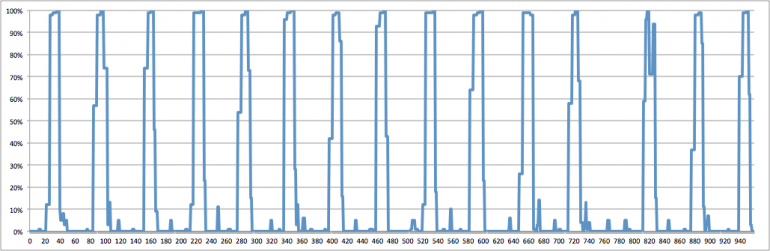
Keras typically performs the estimations of the batches in parallel nevertheless due to Python’s GIL (Global Interpreter Lock) you can’t really achieve true multi-threading in Python. There are two solutions for that: either use multiple processes (note that there are lots of gotchas in this one that I’m not going to cover here) or keep your preprocessing step simple. In the past I’ve sent a Pull-Request on Keras to alleviate some of the unnecessary strain that we were putting on the CPUs during Image preprocessing, so most users should not be affected if they use the standard generators. If you have custom generators, try to push as much logic as possible to C libraries such as Numpy because some of these methods actually release the GIL which means that you can increase the degree of parallelization. A good way to detect whether you are facing GPU data starvation is to monitor the GPU utilization, nevertheless be warned that this is not the only reason for observing that (the synchronization that happens during training across the multiple GPUs is also to blame for low utilization). Typically GPU data starvation can be detected by observing GPU bursts followed by long pauses with no utilization. In the past I’ve open-sourced an extension for Dstat that can help you measure your GPU utilization, so have a look on the original blog post.
Say you used the mutli_gpu_model method to parallelize your model, the training finished and now you want to persist its weights. The bad news is that you can’t just call save() on it. Currently Keras has a limitation that does not allow you to save a parallel model. There are 2 ways around this: either call the save() on the reference of the original model (the weights will be updated automatically) or you need to serialize the model by chopping-down the parallelized version and cleaning up all the unnecessary connections. The first option is way easier but on the future I plan to open-source a serialize() method that performs the latter.
Unfortunately at the moment, there is a nasty side-effect on the tensorflow.python.client.device_lib.list_local_devices() method which causes a new TensorFlow Session to be created and the initialization of all the available GPUs on the system. This can lead to unexpected results such as viewing more GPUs than specified or prematurely initializing new sessions (you can read all the details on this pull-request). To avoid similar surprises you are advised to use Keras’ K.get_session().list_devices() method instead, which will return you all the currently registered GPUs on the session. Last but not least, keep in mind that calling the list_devices() method is somehow expensive, so if you are just interested on the number of available GPUs call the method once and store their number on a local variable.
That’s it! Hope you found this list useful. If you found other gotchas/tips for GPU training on Keras, share them below on the comments. 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more








Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


38% CPU on a 64G machine memory at 19%, two GPU at 60% average. And the GPU is very very spiky. reducing batch size from 32 to 16 somewhat improves GPU not a lot.
Keras, using images flow_from_directory
any guesses