 Sentiment Analysis (detecting document’s polarity, subjectivity and emotional states) is a difficult problem and several times I bumped into unexpected and interesting results. One of the strangest things that I found is that despite the fact that neutral class can improve under specific conditions the classification accuracy, it is often ignored by most researchers.
Sentiment Analysis (detecting document’s polarity, subjectivity and emotional states) is a difficult problem and several times I bumped into unexpected and interesting results. One of the strangest things that I found is that despite the fact that neutral class can improve under specific conditions the classification accuracy, it is often ignored by most researchers.
During my research for my MSc Thesis, I bumped into some interesting properties of Neutral class and Max Entropy classifier. Originally we discussed with my supervisors the possibility of submitting an article about my findings, nevertheless due to my lack of time I decided not to. In this article I decided to present a light version of a part of my research and I am discussing the importance of Neutral class in sentiment analysis.
A similar classifier as described below is used by Datumbox’s Sentiment Analysis service and this powers up our API.
In Sentiment analysis, the neutrality is handled in various ways, depending on the technique that is being used. In lexicon-based techniques the neutrality score of the words is taken into account in order to either detect neutral opinions (Ding and Liu, 2008) or filter them out and enable algorithms to focus on words with positive and negative sentiment (Taboada et al, 2010).
On the other hand when statistical techniques are used, the way that neutrals are handled differs significantly. Some researchers consider that the objective (neutral) sentences of the text are less informative and thus they filter them out and focus only on the subjective statements in order to improve the binary classification (Bo Pang and Lillian Lee, 2002).In other cases they use hierarchical classification where the neutrality is determined first and sentiment polarity is determined second (Wilson et al, 2005).
Finally in most academic papers of sentiment analysis that use statistical approaches, researchers tend to ignore the neutral category under the assumption that neutral texts lie near the boundary of the binary classifier. Moreover it is assumed that there is less to learn from neutral texts comparing to the ones with clear positive or negative sentiment.
Koppel and Schler (2006) showed in their research both of the above assumptions are false. They suggested that as in every polarity problem three categories must be identified (positive, negative and neutral) and that the introduction of the neutral category can even improve the overall accuracy. Their work was primarily focused on SVM and they used geometric properties in order to improve the accuracy of their three binary classifiers.
An intuitive explanation of why neutral class is important is the following: Not all things are black and white and not all sentences have a sentiment. How would you classify the sentence “the weather is hot”? Is it positive or negative? It certainly does not provide any clue about whether the author likes this or not. The neutral class should not be considered as a state between positive and negative but as a separate class that denotes the lack of sentiment.
Also have in mind that when you use only 2 classes you basically force the features/words to be classified as either positive or negative leaving no room for neutrality. By doing so, we can dump into overfitting and become vulnerable to situations where due to randomness a particular neutral word occurs more times in positive or negative examples. Professors Koppel and Schler published a paper about this called “The Importance of Neutral Examples for Learning Sentiment” which I highly recommend you to read.
In my Thesis I studied closely the problem and I wrote several classifiers including 3 Naïve Bayes variations (Multinomial, Binarized and Bernoulli), Max Entropy, SVMs, Softmax Regression, Adaboost and more. In the early stages of the research I tested all of them and based on the initial results I eliminated some of them by using several criteria such as: The overall accuracy, the variation across different datasets, the training and evaluation speed, their ability to parse large amount of data and the amount of resources that they use in terms of CPU and RAM. The selected classifiers were Max Entropy, Mutual Naïve Bayes, Binarized Naïve Bayes and SoftMax Regression.
My target was to build a classifier that is capable of detecting the sentiment in multiple domains. Thus the training dataset that I used came by combining a large number of well-known datasets from various topics. The final training dataset was balanced and had an equal number of examples in each class.
Originally I tested several feature selection algorithms including the Chi-square and the Mutual Information with different number of selected features. At the end I selected Chi-square because it provided better results for most classifiers. Below I present the results for algorithms that use the top 3000 bigrams extracted from 30000 examples.
During my research I tested various scenarios such as including and not including the neutral class, using single 3-class vs 3 binary classifiers and more. In this article I will focus only on the results of 3-class vs the 2-class classifiers because the 3-class outperformed the multiple binary classifiers.
Finally to evaluate the performance of the classifiers I use the average accuracy and to estimate it I performed a 10 fold cross validation.
Below we compare the average accuracy of 4 classifiers with and without the neutral class:
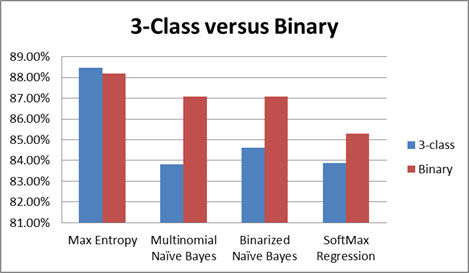
Average accuracy of 3-class and binary classification for 4 different classifiers
Max Entropy classifier provided better results for classification on multi-domain Sentiment Analysis and thus below I focus on this classifier. Based on the above chart Max Entropy is the only classifier that benefits marginally from the introduction of the neutral class. Moreover we can clearly see that Max Entropy outperforms all the other classifiers both for 3-class and for binary classifiers.
In order to ensure that the improvement of the overall accuracy can be reproduced, I use the same approach in various well-known datasets. Below I present the results of 3-class Max Entropy classifier versus Binary Max Entropy classifier for 3 commonly used datasets.
|
Pos/Neg Dataset |
3-class Max Entropy |
Binary Max Entropy |
Neutral Dataset |
| Polarity Dataset V2.0 (movie reviews) |
88.50% |
85.00% |
Subjectivity.MultilingualTrainingData_v2.0 (neutral sentences from various topics) |
| Polarity Dataset V2.0 (movie reviews) |
89.50% |
85.00% |
Subjectivity Dataset V1.0 (neutral texts from the same topic: movie plots) |
| Multi-Domain Sentiment Dataset (product reviews) |
80.97% |
78.50% |
Sentiment analysis Dataset (neutral sentences from various topics) |
Accuracy of Max Entropy for 3-Class and Binary classification
The binary classifier was trained only by using the pos/neg dataset, while the 3-class classifier was trained by using both the pos/neg and the Neutral datasets. In all cases we used the same optimal configuration of Max Entropy classifier as we described it in section 6.5. To test the accuracy we used again the 10-fold cross validation method, training our classifier with 90% of the pos/neg dataset and testing it with the rest 10%. As we can clearly see in all cases, the accuracy of 3-class classifier is better than the one of the binary classifier.
My findings can be summarized to the following: If we want to build a Max Entropy classifier that detects positive and negative texts, we can achieve better accuracy if we train it to detect positive, negative and neutral documents. The accuracy of the 3-class classifier will be higher compared to the two class classifier even if we evaluate only positive and negative documents.
We should also note that in all of the above cases, the testing data did not contain any neutral examples. Thus even though a very small percentage of documents (1.5-3% depending on the dataset) were falsely classified as neutral, all of them were considered as misclassifications. As a result, if we know beforehand that no neutral documents exist within our testing dataset, then we can arbitrary map the neutrals to either positive or negative and gain some additional 1-1.5% of accuracy.
As we saw earlier, Max Entropy is the only classifier that benefits from the introduction of neutral category. This is because Max Entropy principle states that our model should only take into account the important features, constrain our model to the expected probabilities of those features and use the closest to uniform model that satisfies our constrains. In simple words, the Max Entropy principle tells us to avoid any extrapolations/false assumptions and focus only to the things that we do know.
The introduction of the neutral category is fully aligned with the above principle. Within all documents there are words that do not have any sentiment orientation. By using binary classifiers we force the algorithm to put those neutral words to either the positive or negative category. Nevertheless if we choose to use a 3-class classifier, we avoid the above false assumptions and false extrapolations and thus we reduce overfitting. Obviously this is a property that applies only when we use 3-class classifiers and it does not work with multiple binary classifiers.
Another reason why the neutral category can improve accuracy is because it enables the feature selection algorithm to select features of higher quality. Again this property applies only to 3-class classifiers.
Also as we know not all documents are either positive or negative; neutral documents also exist. Koppel and Schler (2006) mentioned on their research that Neutral is not a state between positive and negative. Neutral is the lack of sentiment and this category must be detected in sentiment analysis. In their work they used the geometric properties of Support Vector Machines to assist their classifiers separate the positives from the negatives. This idea applies also in Maximum Entropy when we use a 3-class classifier. This is because as mentioned earlier, the feature selection algorithm selects better features and the Maximum Entropy algorithm assigns better weights to them, making it easier to separate the positive from the negative documents.
I tried to present an as easy as possible explanation of the above without at the same time missing important information about the methodology. If you have any questions or objections concerning the method that I used, leave your message below. I’ll be happy to provide more information or learn from what you have to suggest! 🙂
Did you like the article? Please take a minute to share it on Twitter. 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more








Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


Hi Kory,
Thanks for your comment.
As I described on a previous article “How to build your own Twitter Sentiment Analysis Tool“, Sentiment Analysis on Twitter is a different story. I found that Naive Bayes delivers better results comparing to Max Entropy for twitter sentiment analysis and obviously the introduction of neutral class reduces the accuracy (since only Max Entropy benefits from it). You can read the rest of the previous article.
For neutral dataset in twitter I used mainly tweets coming from newspapers, magazines etc. The reasoning behind this is that usually such tweets state the facts without having sentiment.
Finally yes I did achieve accuracy of over 87% in some specific datasets. Note that this percentage is not for twitter but rather for long texts. I also provide links in this article for the datasets that I used and I fully described the method so you can reproduce the results.
If you have any other question let me know. 🙂
In Naive Bayes you always use the maximum a posteriori (MAP) decision rule. Similar rules are also applied in most methods. Also note that getting equal probabilities is quite rare; if this happens based on your model you can select any of the classes since they have equal probabilities. Again this is not something that I just do in my research, this is a very common practice in Machine Learning applications. I have already written a tutorial about the Naive Bayes model which I plan to publish soon and there I explain how exactly the selection is done.
Finally let me explain what I mean by the paragraph that you quoted. Since I train the classifiers with a dataset that includes neutral examples, the neutral class can be predicted by the model even when you evaluate ONLY positive and negative examples. In this case though out my research I measure all these classifications as mistakes; this was roughly 1.5-3% of the results depending the dataset. Nevertheless if you know before hand that you have only positive and negative texts to evaluate then you can ignore the neutral classification and select the next largest class or arbitrarily map the neutrals in one of the other classes. In this way you will score some additional accuracy points.
Hi Ben,
Thanks for the comment. I was encouraged to publish the research and submit a paper nevertheless at that moment I did not have the time to do it. Perhaps on the future. 🙂
PS: Obviously Dr Koppen and Schler are not processors… 😛 I fixed the typo, thanks!
Thank you @Akshay Khare,
I will publish more on text classification soon and more particularly a tutorial on Maximum Entropy classifier but I have not got the chance to do it yet. Stay tuned.
Cheers!
There is an article on Max Entropy in this Blog. Check out the references. 🙂
I am going to do Sentiment Analysis over tweets about a specific topic to understand how much people are with or against that topic. With only pos/neg labels, we reach to about 85% of accuracy but when we decided to include neutrals, it dropped to about 55% of accuracy. We have about 25,000 tweets for each label. We use BERT for feature extraction and a FC for classifying with max softmax. So, what else I can do to outperform it? Regards