 In text classification, the feature selection is the process of selecting a specific subset of the terms of the training set and using only them in the classification algorithm. The feature selection process takes place before the training of the classifier.
In text classification, the feature selection is the process of selecting a specific subset of the terms of the training set and using only them in the classification algorithm. The feature selection process takes place before the training of the classifier.
Update: The Datumbox Machine Learning Framework is now open-source and free to download. Check out the package com.datumbox.framework.machinelearning.featureselection to see the implementation of Chi-square and Mutual Information Feature Selection methods in Java.
The main advantages for using feature selection algorithms are the facts that it reduces the dimension of our data, it makes the training faster and it can improve accuracy by removing noisy features. As a consequence feature selection can help us to avoid overfitting.
The basic selection algorithm for selecting the k best features is presented below (Manning et al, 2008):
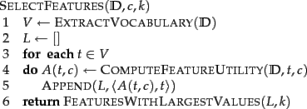
On the next sections we present two different feature selection algorithms: the Mutual Information and the Chi Square.
One of the most common feature selection methods is the Mutual Information of term t in class c (Manning et al, 2008). This measures how much information the presence or absence of a particular term contributes to making the correct classification decision on c. The mutual information can be calculated by using the following formula:
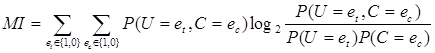 [1]
[1]
In our calculations, since we use the Maximum Likelihood Estimates of the probabilities we can use the following equation:
![]() [2]
[2]
Where N is the total number of documents, Ntcare the counts of documents that have the values et (occurrence of term t in the document; it takes the value 1 or 0) and ec(occurrence of document in class c; it takes the value 1 or 0) that indicated by two subscripts, ![]() and
and ![]() . Finally we must note that all the aforementioned variables take non-negative values.
. Finally we must note that all the aforementioned variables take non-negative values.
Another common feature selection method is the Chi Square. The x2 test is used in statistics, among other things, to test the independence of two events. More specifically in feature selection we use it to test whether the occurrence of a specific term and the occurrence of a specific class are independent. Thus we estimate the following quantity for each term and we rank them by their score:
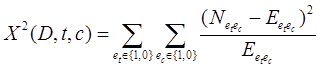 [3]
[3]
High scores on x2 indicate that the null hypothesis (H0) of independence should be rejected and thus that the occurrence of the term and class are dependent. If they are dependent then we select the feature for the text classification.
The above formula can be rewritten as follows:
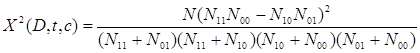 [4]
[4]
If we use the Chi Square method, we should select only a predefined number of features that have a x2 test score larger than 10.83 which indicates statistical significance at the 0.001 level.
Last but not least we should note that from statistical point the Chi Square feature selection is inaccurate, due to the one degree of freedom and Yates correction should be used instead (which will make it harder to reach statistical significance). Thus we should expect that out of the total selected features, a small part of them are independent from the class). Thus we should expect that out of the total selected features, a small part of them are independent from the class. Nevertheless as Manning et al (2008) showed, these noisy features do not seriously affect the overall accuracy of our classifier.
Another technique which can help us to avoid overfitting, reduce memory consumption and improve speed, is to remove all the rare terms from the vocabulary. For example one can eliminate all the terms that occurred only once across all categories. Removing those terms can reduce the memory usage by a significant factor and improved the speed of the analysis. Finally we should not that this technique can be used in conjunction with the above feature selection algorithms.
Did you like the article? Please take a minute to share it on Twitter. 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more








Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


Have you tried it in practice, or is this a theoretical take?
What about lasso instead of the fancy equations?
https://fastml.com/large-scale-l1-feature-selection-with-vowpal-wabbit/
Yes I have heavily used them in practice in the past. Check this out: https://blog.datumbox.com/developing-a-naive-bayes-text-classifier-in-java/
Dear “Someone”,
Thank you for the feedback; I wish you have written your name/email instead of using Someone/fake.unique.username@gmail.com. I believe that when you express your opinion you should not remain anonymous.
At any case, I always try to describe everything as simple as possible and provide useful references for those who want to read more. As you will see in this article I provide more than enough references in the links. Keep in mind that I am writing blogposts not a book on Machine Learning, so it is not always feasible to write lengthy explanations.
I don’t agree with your comment concerning “writing down formulas” in order to “advertise yourself as an expert”. First of all the above formulas are way way waaaaaaay too simple and nobody will consider me an expert for writing them. Moreover real experts tend to be able to explain everything in a clear and easy to understand way. This comes from the fact that they have deep knowledge on the topic. 😉
Best Regards,
Vasilis
Thanks for this brief explanation. Short, sweet, and to the point! I needed a crash course on using Chi-Square for feature selection. Nothing too in-depth, just enough to code it for a short project. This blog post did the job!
Hi Vasilis Vryniotis
I want to ask about Chi Square method.
Why it critical value has to be 10.83