 The ALS algorithm introduced by Hu et al., is a very popular technique used in Recommender System problems, especially when we have implicit datasets (for example clicks, likes etc). It can handle large volumes of data reasonably well and we can find many good implementations in various Machine Learning frameworks. Spark includes the algorithm in the MLlib component which has recently been refactored to improve the readability and the architecture of the code.
The ALS algorithm introduced by Hu et al., is a very popular technique used in Recommender System problems, especially when we have implicit datasets (for example clicks, likes etc). It can handle large volumes of data reasonably well and we can find many good implementations in various Machine Learning frameworks. Spark includes the algorithm in the MLlib component which has recently been refactored to improve the readability and the architecture of the code.
Spark’s implementation requires the Item and User id to be numbers within integer range (either Integer type or Long within integer range), which is reasonable as this can help speed up the operations and reduce memory consumption. One thing I noticed though while reading the code is that those id columns are being casted into Doubles and then into Integers at the beginning of the fit/predict methods. This seems a bit hacky and I’ve seen it put unnecessary strain on the garbage collector. Here are the lines on the ALS code that cast the ids into doubles:


To understand why this is done, one needs to read the checkedCast():
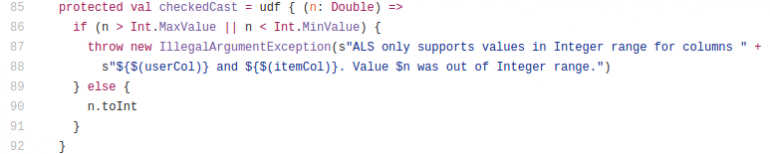
This UDF receives a Double and checks its range and then casts it to integer. This UDF is used for Schema validation. The question is can we achieve this without using ugly double castings? I believe yes:
protected val checkedCast = udf { (n: Any) =>
n match {
case v: Int => v // Avoid unnecessary casting
case v: Number =>
val intV = v.intValue()
// True for Byte/Short, Long within the Int range and Double/Float with no fractional part.
if (v.doubleValue == intV) {
intV
}
else {
throw new IllegalArgumentException(s"ALS only supports values in Integer range " +
s"for columns ${$(userCol)} and ${$(itemCol)}. Value $n was out of Integer range.")
}
case _ => throw new IllegalArgumentException(s"ALS only supports values in Integer range " +
s"for columns ${$(userCol)} and ${$(itemCol)}. Value $n is not numeric.")
}
}
The code above shows a modified checkedCast() which receives the input, checks asserts that the value is numeric and raises exceptions otherwise. Since the input is Any, we can safely remove all the cast to Double statements from the rest of the code. Moreover it is reasonable to expect that since the ALS requires ids within integer range, the majority of people actually use integer types. As a result on line 3 this method handles Integers explicitly to avoid doing any casting. For all other numeric values it checks whether the input is within integer range. This check happens on line 7.
One could write this differently and explicitly handle all the permitted types. Unfortunately this would lead to duplicate code. Instead what I do here is convert the number into Integer and compare it with the original Number. If the values are identical one of the following is true:
To ensure that the code runs well I tested it with the standard unit-tests of Spark and manually by checking the behavior of the method for various legal and illegal values. To ensure that the solution is at least as fast as the original, I tested numerous times using the snippet below. This can be placed in the ALSSuite class in Spark:
test("Speed difference") {
val (training, test) =
genExplicitTestData(numUsers = 200, numItems = 400, rank = 2, noiseStd = 0.01)
val runs = 100
var totalTime = 0.0
println("Performing "+runs+" runs")
for(i <- 0 until runs) {
val t0 = System.currentTimeMillis
testALS(training, test, maxIter = 1, rank = 2, regParam = 0.01, targetRMSE = 0.1)
val secs = (System.currentTimeMillis - t0)/1000.0
println("Run "+i+" executed in "+secs+"s")
totalTime += secs
}
println("AVG Execution Time: "+(totalTime/runs)+"s")
}
After a few tests we can see that the new fix is slightly faster than the original:
|
Code |
Number of Runs |
Total Execution Time |
Average Execution Time per Run |
| Original | 100 | 588.458s | 5.88458s |
| Fixed | 100 | 566.722s | 5.66722s |
I repeated the experiments multiple times to confirm and the results are consistent. Here you can find the detailed output of one experiment for the original code and the fix. The difference is small for a tiny dataset but in the past I’ve managed to achieve a noticeable reduction in GC overhead using this fix. We can confirm this by running Spark locally and attaching a Java profiler on the Spark instance. I opened a ticket and a Pull-Request on the official Spark repo but because it is uncertain if it will be merged, I thought to share it here with you and it is now part of Spark 2.2.
Any thoughts, comments or critisism are welcome! 🙂
My name is Vasilis Vryniotis. I'm a Machine Learning Engineer and a Data Scientist. Learn more



")




Datumbox offers an open-source Machine Learning Framework and an easy to use and powerful API.
Subscribe to our newsletter and get our latest news!
2013-2026 © Datumbox. All Rights Reserved. Privacy Policy | Terms of Use


Hi sir,
My name is Girish from Karnataka.India (BSc , MCA)
I would like to do research in the field of sentimental analysis.I don’t know no where to start .can you help me in this regard or can you suggest some problem statement. I know Java and R programming.
its very detailed blog on ALS. very informative. Thanks man
One quick question since you have done such detailed investigation already is about normalization of the counts
Do we need to normalize the matrix and if yes what’s the best way